tensorflow学习笔记(4):Activation Functions
Activation functions are a cornerstone of Machine Learning. In general, Activation Functions define how a processing unit will treat its input — usually passing this input through it and generating an output through its result. To begin the process of having a more intuitive understanding, let’s go through some of the most commonly used functions.
Importing Dependencies
import tensorflow as tf |
The next cell implements a basic function that plots a surface for an arbitrary activation function. The plot is done for all possible values of weight and bias between -0.5 and 0.5 with a step of 0.05. The input, the weight, and the bias are one-dimensional. Additionally, the input can be passed as an argument.
def plot_act(i=1.0, actfunc=lambda x: x): |
Basic Structure
In this example we illustrate how, in Tensorflow, to compute the weighted sum that goes into the neuron and direct it to the activation function. For further details, read the code comments below.
#start a session |
plot_act(1.0, func) |
The Step Functions
The Step function was the first one designed for Machine Learning algorithms. It consists of a simple threshold function that varies the Y value from 0 to 1. This function has been historically utilized for classification problems, like Logistic Regression with two classes.
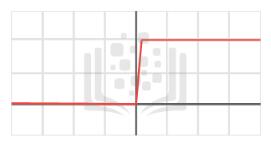
The Step Function simply functions as a limiter. Every input that goes through this function will be applied to gets either assigned a value of 0 or 1. As such, it is easy to see how it can be handy in classification problems.
There are other variations of the Step Function such as the Rectangle Step and others, but those are seldom used.
Tensorflow dosen’t have a Step Function.
The Sigmoid Functions
The next in line for Machine Learning problems is the family of the ever-present Sigmoid functions. Sigmoid functions are called that due to their shape in the Cartesian plane, which resembles an “S” shape.
Sigmoid functions are very useful in the sense that they “squash” their given inputs into a bounded interval. This is exceptionally handy when combining these functions with others such as the Step function.
Most of the Sigmoid functions you should find in applications will be the Logistic, Arctangent, and Hyperbolic Tangent functions.
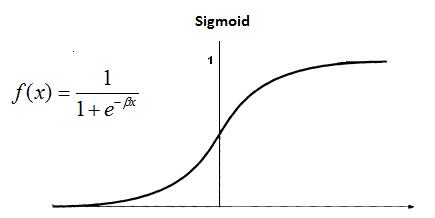
Logistic Regression (sigmoid)
The Logistic function, as its name implies, is widely used in Logistic Regression. It is defined as $f(x) = \dfrac{1}{1 + e^{-x}}$. Effectively, this makes it so you have a Sigmoid over the $(0,1)$ interval, like so:
plot_act(1, tf.sigmoid) |
3D sigmoid plot. The x-axis is the weight, the y-axis is the bias.
Using sigmoid in a neural net layer
act = tf.sigmoid(tf.matmul(i, w) + b) |
The Arctangent and Hyperbolic Tangent functions on the other hand, as the name implies, are based on the Tangent function. Arctangent is defined by $f(x) = tan^{-1}x$, and produces a sigmoid over the $(\dfrac{-\pi}{2},\dfrac{\pi}{2})$ interval.
It has no implementation in Tensorflow
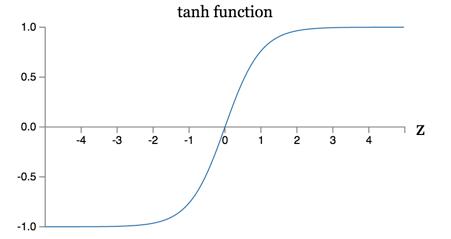
Tanh
The Hyperbolic Tangent, or TanH as it’s usually called, is defined as $f(x) = \dfrac{2}{1 + e^{-2x}} - 1$. It produces a sigmoid over the $(-1,1)$ interval. TanH is widely used in a wide range of applications, and is probably the most used function of the Sigmoid family.
plot_act(1, tf.tanh) |
3D tanh plot. The x-axis is the weight, the y-axis is the bias.
Using tanh in a neural net layer
act = tf.tanh(tf.matmul(i, w) + b) |
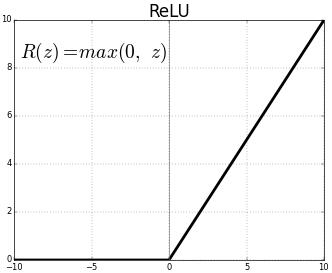
The Linear Unit functions
Linear Units are the next step in activation functions. They take concepts from both Step and Sigmoid functions and behave within the best of the two types of functions. Linear Units in general tend to be variation of what is called the Rectified Linear Unit, or ReLU for short.
The ReLU is a simple function which operates within the $[0,\infty)$ interval. For the entirety of the negative value domain, it returns a value of 0, while on the positive value domain, it returns $x$ for any $f(x)$.
While it may seem counterintuitive to utilize a pseudo-linear function instead of something like Sigmoids, ReLUs provide some benefits which might not be understood at first glance. For example, during the initialization process of a Neural Network model, in which weights are distributed at random for each unit, ReLUs will only activate approximately only in 50% of the times — which saves some processing power. Additionally, the ReLU structure takes care of what is called the Vanishing and Exploding Gradient problem by itself. Another benefit — if not only marginally relevant to us — is that this kind of activation function is directly relatable to the nervous system analogy of Neural Networks (this is called Biological Plausibility).
The ReLU structure has also has many variations optimized for certain applications, but those are implemented on a case-by-case basis and therefore aren’t in the scope of this notebook. If you want to know more, search for Parametric Rectified Linear Units or maybe Exponential Linear Units.
plot_act(1, tf.nn.relu) |
3D relu plot. The x-axis is the weight, the y-axis is the bias.
Using relu in a neural net layer
TensorFlow has ReLU and some other variants of this function. Take a look:
act = tf.nn.relu(tf.matmul(i, w) + b) |
This is the end of the Activation Functions notebook. Hopefully, now you have a deeper understanding of what activation functions are and what they are used for. Thank you for reading this notebook, and good luck on your studies.
You can take a look at all TensorFlow Activation Functions in its reference.
