
arxiv论文类别
arxiv
cs.AI - 人工智能 - Artificial Intelligence
cs.CL - 计算与语言 - Computation and Language (Computational Linguistics and Natural Language and Speech Processing)
cs.CR - 加密与安全 - Cryptography and Security
cs.CV - 机器视觉与模式识别 - Computer Vision and Pattern Recognition
cs.CY - 计算与社会 - Computers and Society
cs.DC - 分布式、并行与集群计算 - Distributed, Parallel, and Cluster Computing
cs.DS - 数据结构与算法 - Data Structures and Algorithms
cs.HC - 人机接口 - Human-Computer Interaction
cs.IR - 信息检索 - Information Retrieval
c ...

jupyter中添加kernel
jupyter中添加kernel
首先激活conda环境: source activate 环境名称
安装ipykernel:conda install ipykernel
将环境写入notebook的kernel中 python -m ipykernel install --user --name 环境名称 --display-name "Python (环境名称)"
删除kernel环境:jupyter kernelspec remove 环境名称
jupyter config
one of the answerjupyter notebook can not open browser selfhttps://support.anaconda.com/customer/en/portal/articles/2925919-change-default-browser-in-jupyter-notebook
jupyter themes
终端配置
jt -t onedork -fs 11 -nfs 11
notebook 配置
# import jtplot module in notebookfrom jupyterthemes import jtplot# choose which theme to inherit plotting style from# onedork | grade3 | oceans16 | chesterish | monokai | solarizedl | solarizeddjtplot.style(theme='onedork')# set "context" (paper, ...
![目标检测中符号mAP,mAP@[0.5], mAP@[0.5:0.95]是什么意思?](https://cdn.jsdelivr.net/gh/busyboxs/CDN@latest/covers/object_detection.jpg)
目标检测中符号mAP,mAP@[0.5], mAP@[0.5:0.95]是什么意思?
one of the answerFor detection, a common way to determine if one object proposal was right is Intersection over Union(IoU). This takes the set A of proposed object pixels and the set of true object pixels B and calculates:
IoU(A, B) = \frac{A \cap B}{A \cup B}
Commonly, IoU > 0.5 means that it was a hit, otherwise it was a fail. For each class, one can calculate the
True Positive (TP(c)): a proposal was made for class c and there actually was an object of class c
False Positive (FP(c)): a pr ...
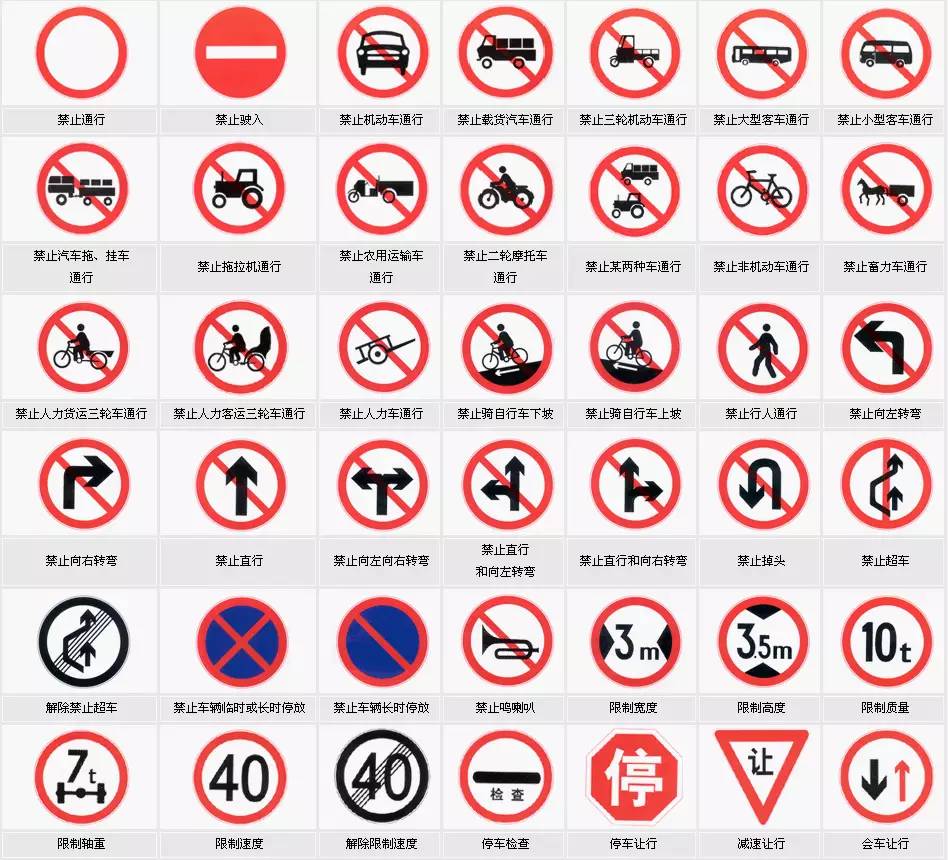
【译】基于深度学习的交通标志分类
可以在这里找到代码。它可能比文章更新;
介绍这是自动驾驶系列的第二篇文章。如果想知道为什么我要分享这个以及更多关于我的经历,请阅读这篇博客。
目标使用简单的卷积神经网络对交通标志进行分类。
机器学习想象一下,你需要建立一个识别手写体数字的程序。
这是5。但也可以说是3。
你会用什么规则来判断它是3还是5呢?
研究人员决定向计算机展示成千上万的例子,并试图通过经验来解决问题,而不是试图挑选所有规则并构建一个非常复杂的程序。这是机器学习的开始。
机器学习的主要问题之一是特征提取。尽管我们向计算机展示了成千上万的例子,但我们仍然需要告诉他应该关注哪些特征。对于复杂问题,这还不够好。
深度学习模型绕过了这一点。它们自己学习应该关注哪些特征。
深度学习为了简洁起见,我不打算深入深度学习的数学解释。我花了大约20个小时来理解这些概念并使用它们。相反,我会尝试解释深度学习背后的原因。如果你想要更深入,我会发布一些我用过的视频和讲座。
作为人类,识别物体似乎是一项非常简单的任务。我们几乎不用做任何努力,至少不是有意识的。但在我们真正了解我们正在看的东西之前,我们的大脑实际上已经完成了很多工作。
在2 ...

【译】Tensorflow 与 Keras?通过构建图像分类模型来比较
原文地址: https://hackernoon.com/tensorflow-vs-keras-comparison-by-building-a-model-for-image-classification-f007f336c519
是的,标题中的问题在数据科学家之间的谈话中是很常见(甚至你!)。有人说TensorFlow更好,有人说Keras更好!让我们看看这个问题在图像分类的实际应用中的答案。
在此之前,先介绍Keras和Tensorflow这两个术语,帮助你在10分钟内构建强大的图像分类器!
Tensorflow:Tensorflow是开发深度学习模型最常用的库。它是有史以来最好的库,在日常实验中被许多极客选择。如果我说Google已经将Tensor Processing Units(TPU)用于处理张量,你能想象吗?是的,他们已经这样做了。他们提出了一个名为TPU的独立实例,它具有最强大的功率驱动计算能力来处理tensorflow的深度学习模型。
Time to BUILD IT!(是时候建立它了!)我现在将帮助你使用tensorflow创建一个功能强大的图像分类器。等等! ...
通过分析实例来理解TFRecord数据的读取与写入
本文主要通过两个实例来加强对TFRecord数据的理解,分别为目标检测算法SSD和语义分割算法deeplab。仅作为学习笔记以便后续查阅。
TFRecord简介TFRecords文件表示字符串序列(二进制文件)。其格式不是随机访问的,因此它适用于流式传输大量数据,但如果需要快速分片或其他非顺序访问则不适用。
TFRecords文件包含CRC32C(使用Castagnoli多项式的32位CRC)哈希值的字符串序列。每条记录都有以下格式
uint64 lengthuint32 masked_crc32_of_lengthbyte data[length]uint32 masked_crc32_of_data
这些记录连接在一起以生成文件。更多CRC的描述参阅这里,CRC的掩码形式如下:
masked_crc = ((crc >> 15) | (crc << 17)) + 0xa282ead8ul
SSD中TFRecord的使用SSD是一种目标检测方法。本节中使用到的代码主要来自于SSD-Tensorflow。本节主要包括数据集的介绍,TFRecord数据写入 ...
TFRecord 是什么?如何使用?
原文地址:Tensorflow Records? What they are and how to use them
自2015年11月推出以来,对 Tensorflow 的兴趣稳步增长。Tensorflow 的一个鲜为人知的组件是 TFRecord 文件格式,它是Tensorflow自己的二进制存储格式。
如果您正在处理大型数据集,则使用二进制文件格式存储数据会对导入pipeline的性能产生重大影响,从而影响模型的训练时间。二进制数据在磁盘上占用的空间更少,复制时间更短,并且可以从磁盘更有效地读取。如果您的数据存储在机械磁盘(spinning disks)上,尤其如此,因为与SSD相比,机械磁盘读/写性能要低得多。
但是,纯粹的性能并不是TFRecord文件格式的唯一优势。它针对Tensorflow以多种方式进行了优化。首先,它可以轻松组合多个数据集,并与库提供的数据导入和预处理功能无缝集成。特别是对于太大而无法完全存储在存储器中的数据集,这是一个优点,因为只有所需的数据(例如一个batch)从磁盘加载然后被处理。TFRecords的另一个主要优点是可以存储序列数据,例如,时间序列 ...

使用git上传文件或文件夹到github repository
通过SSH连接GitHub使用SSH协议,您可以连接并验证远程服务器和服务。使用SSH密钥,您可以连接到GitHub,而无需在每次访问时提供您的用户名或密码。
生成一个新的SSH密钥并将其添加到ssh-agent在检查了现有的SSH密钥后,可以生成一个新的SSH密钥用于身份验证,然后将其添加到ssh-agent。
如果您还没有SSH密钥,则必须生成一个新的SSH密钥。如果您不确定是否已有SSH密钥,请检查现有密钥。
检查现有的SSH密钥
打开终端;
输入ls -al ~/.ssh以查看是否存在现有的SSH密钥:
$ ls -al ~/.ssh# Lists the files in your .ssh directory, if they exist
检查目录列表,看看你是否已经有一个公共的SSH密钥。
默认情况下,公钥的文件名是以下之一:
id_dsa.pub
id_ecdsa.pub
id_ed25519.pub
id_rsa.pub
如果您没有现有的公钥和私钥对,或者不希望使用任何可用于连接到GitHub的公钥和私钥,请生成一个新的SSH密钥。如果您看到列出的现有公 ...

机器学习之岭回归
问题引入
线性模型:$\mathop{min}_{w} {\Vert X w-y \Vert_2}^2$
岭回归: $\mathop{min}_{w} {\Vert X w - y \Vert _2}^2 + {\alpha \Vert w \Vert_2}^2$
lasso:$\mathop{min}_{w} {\Vert X w - y \Vert _2}^2 + {\alpha \Vert w \Vert_1}$
在线性回归中,对于普通最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵 X 的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity) 的情况可能真的会出现。因此,是否可以删除掉一些相关性较强的变量呢?如果p个变量之间具有较强的相关性,那么又应当删除哪几个是比较好的呢?
岭回归思想岭回归通过对系数的大小施加惩罚来解决普通最小二乘法的一些问题。 岭系数最小化一个带罚项的残差平方和,
\math ...
